HTML網頁是由有多個段落所組成,每個段落通常使用<p>標籤,再進行編排,例如段落間添加適當的間距,可以提高可讀性,下面會先介紹編排段落時常用的標籤。
<p>標籤<p>這是第一個段落的文字。</p>
<p align = “center”>
<hr>標籤<h1>標題</h1>
<hr>
<p>段落</p>
<br>標籤步驟與爬取HTML網頁標題相同,只是這一次我們要擷取的內容是<p>標籤,一樣也是使用THE NEWS LENS文章( https://www.thenewslens.com/features )
這邊我就直接跳到建立CSS選擇器,輸入id和Type類型,一樣選用Text類型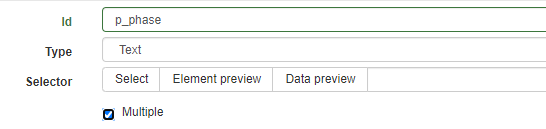
按下選擇器Select,選取段落文字,第一個<p>標籤選取到後,繼續點選第二個,就會選取到所有段落了

後面實作時會完整講解,使用Web Scraper的爬蟲過程~
大家掰掰~明天見

